求人広告を新しくしました。
このたびは
「目を輝かせて仕事をしている人がいます」
です。
現役プログラマーのS君に登場して頂きました!ありがとうー!!

この広告に至った経緯なんですが、最初は
「どんな人に来てほしいかわかる&キャッチーで人目をひく」
ってのを考えていて、
「豆から挽いたコーヒーが飲めます」
にしようかなと思ってたんですが、なんかイマイチだなと。どんな人に来てほしいのかもわかりませんしね!(コーヒーが好きな人が来そうではある(笑))
で、一方社内に目を転じてみると、プログラマーのS君がすごい楽しそうに仕事をしてたんですよ。
ちょっと前からS君が急にすごい勉強するようになって、中でも「ちょうぜつソフトウェア設計入門」と「クリーンアーキテクチャー」という本がすごく気に入ったそうで、
「このクラスはこれこれこうやっていいですか?やっぱり単一責任原則に基づいて設計していかないとですよね!!」
「なるべくインターフェースをいっぱい作ってテストとかを先に作っていきたいです!!」
「クリーンアーキテクチャーにするためにここはモデルにして、この役割はアプリケーションにして…」
とか言って、猛烈に「よい設計」を目指して仕事をするようになったんですよ。
(ちなみに、写真の手に持っている本にもご注目ください( ˊᵕˋ ))
また、S君は効率化ということにとても興味があって、よく画面構成・機能などについても
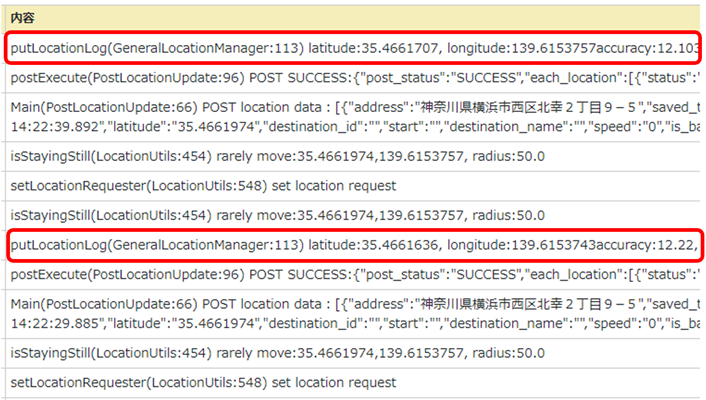
「お客さんは30分以上かかってたら赤くなってたらすぐわかって便利じゃないですか?パッと見でわかるし。」
など顧客目線に立ってどんどんアイデア出してくれます。
S君はまさに目を輝かせてパソコンに向かってました。
私はそれを見て純粋にメチャクチャ嬉しかったですね!( ˊᵕˋ )
そして、社員さんが健全に仕事を楽しんでやってくれているというのは、すごいことなんじゃないかと思います。
ご本人の資質もあると思います。
が、正直楽しめる仕事って世の中に多いですか?
で、ある時
「ん?この状態をそのまま求人広告にしたらいいのでは?」
と思いました。
熱意のある人に来てほしい、という我々の意図も伝わると思いますし!
実は、頭に浮かんでたビジュアル案としては、「推しの子」の星野アイちゃんみたいに目にガッツリと☆を入れたかったんですが。
やっぱり実写だとそれは厳しかったですね
なるべく流行りものを取り入れたいなとは思ってるんで。
ちょっとタイミングがずれてたら、猫ミームになってた可能性はある(笑)
さて、今までも突飛な求人広告をよくやってきてたんですけど、どうしてそういうのにするのか、というのは書いておきたいと思います。
①人目を惹きたい
大きな会社ではないですから、多くの求人広告がスクロールされていく中で目を止めてもらわないといけません。
キャッチーな写真、キャッチーな一言、は必要だなと思います。
②本当にイノベーティブな人に来てほしい
これねー、いろんな価値観はもちろんあるとは思いますが、イノベーティブってなんでしょう?
挑戦すること、革新的な何かを作れること、ですが、私は他の多くの人と違う方向に行ける、ということも一つあると思います。
それって実は、すっごい難しいことなんですよ。
なので、本当にイノベーティブな人を探したいので、ちょっと突飛な求人広告を出しています。
「うわー、こういうのひくわ…。」
という人にはウチの会社はあわないと思うからです。
大手の会社が、
「イノベーティブ人材を求む!」
とか
「チャレンジできる風土です!」
とか、青空をバックに、若いビジネススーツを来た学生の男女がダッシュしてる、みたいなビジュアルの求人広告ってめっちゃ多いですよね(笑)。
そういうので本当にイノベーティブな人が入ってくるのでしょうか?大手の人事部の方に聞いてみたいです。
というわけで、なんとまだ2023年度卒の新卒を募集していますし、第二新卒・中途も募集中です!
今年度も多くの方に応募して頂いております。
ありがとうございます。(>_<)
上述したように、こんな変な求人広告を見て応募してくださっただけで、私としては全員採用したいぐらいですが!
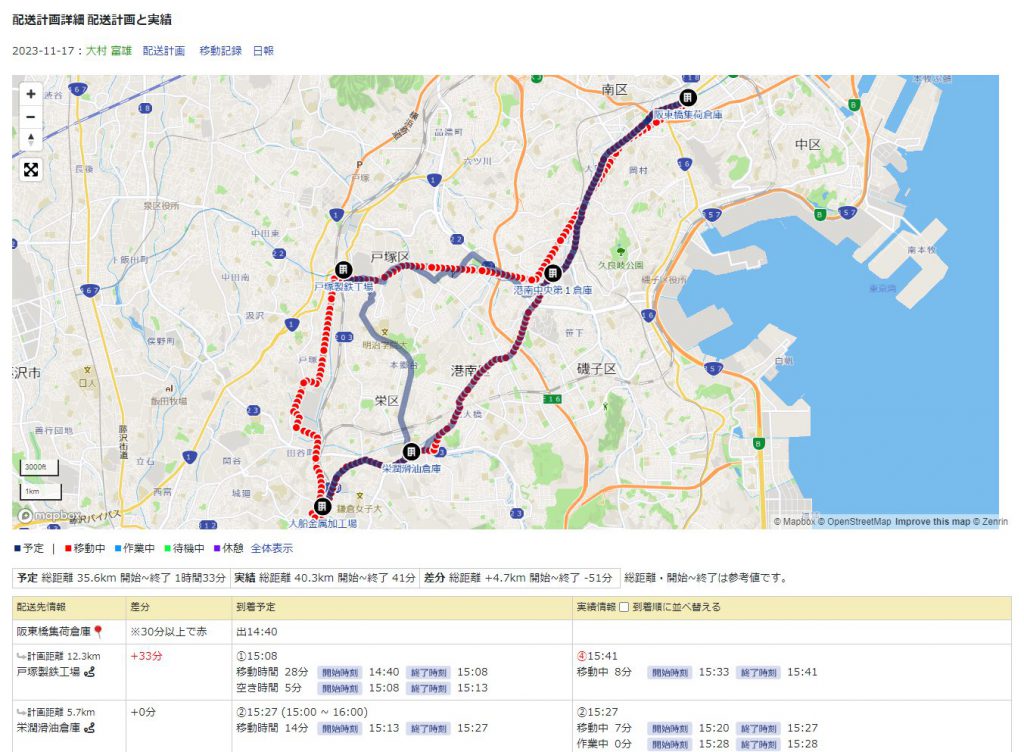
ウチの会社が何をやっているかを改めて書いておくと、配送会社さん向けのシステムです。
スマホの位置情報と配送計画が連動しているのが特徴です。
今まで世の中になかったソフトウェアなんですよ。
「会計システム」「帳票システム」「ショッピングカート」など、今まで世の中に存在した製品ではありません。
だから、イノベーティブな人が必要なんです。
新しく何かを作るということは、楽しく、責任があって、失敗も多い仕事です。
そして、配送・運送の世界って今大変なんですよ 人手不足やガソリン代高騰のところに2024年問題が来ようとしています。
それをお助けするための仕事です。
こんな方↓に来てほしいです。
①弊社の理念と目標に共感し、長い視点で仕事ができる
②コミュニケーション能力が高い人
-「何かを察してほしい」というのではなく、自分で発言できる
– 困った時には誰かに相談できる
– 問題を提起できる
③顧客の問題を理解し、顧客の問題を解決したいという情熱のある人
-自分がお客様気分ではない
-顧客・社会の役に立つことを喜びと思える
④責任感の強い人
– 困難にぶつかったらすぐに何かを放り出したり、他人のせいにするのではなく、自分の責任で自分の仕事をできる人
– 挑戦している人を評論したりするのではなく、自分が挑戦することができる人
– 勉強・成長を続けていける
要はハートだと思ってます。
プログラミングや営業は、今できなかったとしてもガチで我々が教えます!!(`・ω・´)
当てはまるな、という方はぜひエントリーしてください!
エントリーはコチラをお読みの上、問い合わせフォームからご連絡ください。┌o ペコッ